研究読本 Ver 1.7 植松友彦@東京工業大学(URI先PDF)
www.it.ss.titech.ac.jp/uyematsu/howtoresearch
---
自分に足りないもの
・物事を数理的に理解する能力(理論、数学力)
・文献を読み知見を得る能力
・・・その他たくさん
理論周りの勉強や、多くの文献を読むことをないがしろにしてきているので、
このあたりをしっかりとできるようにしていきたい。
2010年7月29日木曜日
逐次音声処理と一括音声処理


(名称は仮のものです)
【前提】
音声処理の所要時間のRTF(実時間係数)とは、処理時間を音声時間で割った値である。
以下におけるレイテンシの議論では、入力データレートがシステムの同時処理限界人数よりも小さい状態を仮定している。
【逐次音声処理】
逐次音声処理は、クライアント側が発声を開始してから逐次エンコーディング、サーバへの送信、音声処理を行っていく方法である。発声が完了しなくても音声処理を開始することが出来るため、発声終了から音声処理を開始するよりも応答時間が短くなる。
音声長を x、音声処理時間のRTF を k, ネットワークなどの固定レイテンシを L とおくと、発声終了からのレイテンシは k が 1.0 よりも大きい場合
≒ (k - 1.0)x + L
と定式化できる。
逆に、k の値が 1.0 より小さいか同程度である場合でも、発声が完了しないと実行できない処理もあるため、レイテンシは
≒ pkx + L
となる。p は音声処理のうち発声が完了してから開始される処理の所要時間の、全処理時間に対する比率 (0 ≦ p <1.0) ならば同時処理限界人数は
≒ n / k
となるが、一方 k ≦ 1.0 の場合、
≒ n
となり、サーバの台数以上に同時処理限界人数を増やすことは出来ない。
【一括音声処理】
一括音声処理では、クライアント側で発声が完了してから、一括でサーバに送信し、音声処理を始める方法である。この手法でのレイテンシは
≒ kx + L
となり、逐次音声処理よりもレイテンシが明らかに大きくなってしまう。これはリアルタイム音声処理では致命的である。
(RTF 1.3 ならば、10秒の音声に対して逐次だと 3+L 秒で済むところが、一括だと 13+L 秒もかかってしまう)
一方スループットは、k の大小に関わらず
≒ n / k
となり、これは RTF が 1.0 よりも小さい場合に同時処理人数が大きく向上することとなる。
つまり、一括音声処理の逐次音声処理に対するアドバンテージとは、音声処理の RTF を 1.0 よりも小さく出来るときに、スループットを向上させることが出来る、という点にあるといえる。
SystemS : TCP周りのメモ
stcp: 経由の user-defined source operator では、通常のソケット通信(サーバ)と異なり、クライアントからの接続が終了したか、を確認することが出来ない。
C や Python などのソケット通信では recv() 関数の戻り値などからそれを判断できる。
SystemS だと、クライアントからの入力途中に突然接続が切れた場合、データが中断されたことを udf-source 内で把握できない。
このため、後続する別のクライアントからのデータを、以前のクライアントからのデータの続きとして扱ってしまうことになる。
(udf-source の実装にもよるが)
このことも少し関連してきて、SystemS 内部での逐次音声認識処理の記述が困難になっていた。
C や Python などのソケット通信では recv() 関数の戻り値などからそれを判断できる。
SystemS だと、クライアントからの入力途中に突然接続が切れた場合、データが中断されたことを udf-source 内で把握できない。
このため、後続する別のクライアントからのデータを、以前のクライアントからのデータの続きとして扱ってしまうことになる。
(udf-source の実装にもよるが)
このことも少し関連してきて、SystemS 内部での逐次音声認識処理の記述が困難になっていた。
2010年7月23日金曜日
StreamSR : 要求入力レート、スループット

入力コア数1、認識コア数4、ビーム幅1500(その他省略)の設定のもとで、Streams内部で求めたスループット限界の値は(音声時間vs実処理時間) 2.21 である。
この条件下で、要求入力データレート(Streamsの外でInputTimeを付与)を 0.5 , 1.0 , 2.0 , 3.0 , 6.0 と変化させたときの、テストセット(音声ファイル30個)に対するレイテンシ、および音声時間を図示する。
図より、入力データレート 0.5 , 1.0 (2.21 より低い)ではレイテンシはほぼ音声時間に比例する値で、これは認識処理自体のレイテンシのみが現れる結果となっている。
一方、入力データレート 3.0 , 6.0 などスループット限界より大きい値のときは、認識コアの処理待ちにより、レイテンシが大きく増大している。
この入力データレートの値は、Streams内部からでも参照可能なので、この値を元に最適ビーム幅を決定することが可能である。
(余談)
図の結果だと入力データレートが低いときでも、例えば10秒の音声に対して15秒ものレイテンシがかかっている。これはリアルタイム音声認識としてはちょっとレイテンシが大きすぎると思う。
レイテンシの下限値については、認識コア数を増やしても(スケールアウトしても)変わらないので、もっと基本的な部分でスケールアップするべき(ビーム幅を下げるとか)。
StreamSR : 負荷の指標

■現在の負荷の指標
AGG_RANGE = 6
最新 AGG_RANGE サンプルから計算される、アイドル時間も含めた、瞬間平均流速
sum(nsamples)/(max(otime)-min(itime)) * 定数
■その値の時間的変化
(入力コア : 1、認識コア : 4)
グラフは、tcpを経由してディレイを与えずに順次データを送信し続けた場合の
瞬間平均流速の変化をプロットしたものである。
見てのとおり、最大スループットが現れるのは入力系列の最初のほうのサンプルである。
バッファリングが生じていないため、itime計測から認識を経てotime計測までの時間が短くなるからである。
このような最大スループットの値からビーム幅変更のスレッショルドを求めるのは難しい気がする。
あるいは、ビーム幅の候補を手動で与えるのと同様に、スレッショルドも手動で与えてもらうような実装なら簡単かも。
最大スループットにある定数 k (0 < k < 1) を乗じた値を
ビーム幅変更のスレッショルドにする、というのも学習機構の簡単な実装の一つ。
2010年7月22日木曜日
StreamSR : 微妙な問題、など
■なぜかstcpが動かない
netstat -l してもポートが表示されない
(追記 : 20100723 Fri)
なんかよくわからないけど直ってた。
start_streams を実行するノードの問題だろうか?
とりあえず se00 から実行すれば問題なさそう
■現実装の思想と実際
(思想)
低負荷時(要求入力速度<認識限界スループット)であれば
レイテンシは認識速度のみに依存
低認識精度でも高認識精度でも、認識処理以外にレイテンシが引っ張られることはない
高負荷時(要求入力速度>認識限界スループット)であれば
高認識精度だとバッファリングが生じるため
低認識精度時に比べレイテンシが激しく増大する
なので高負荷時には認識精度を低く、低負荷時には認識精度を高くしたい
負荷を測る指標として、認識器のアイドル時間も含めた瞬間平均流速を用いる。
この値が指定した範囲に含まれるとき、その範囲に該当するビーム幅を設定する、という実装
(問題)
この「負荷の指標」は正しく負荷を表しているか?
また、「負荷の指標」の値は現在のビーム幅にも依存してしまうという問題もある
(以下、要言語化)
やればわかる。学習機構自体は再考の必要あり?
あるいはごく簡単な学習機構のみを作り、手動で学習済みパラメータの入力も可能にする
学習機構のより適切な実装については論文中で「今後の課題」として書く。
論文の背景:オフライン音声認識、オンライン音声認識などの研究は今までなされてきたが、今日ではデータストリーム処理の重要性なども関連してきて、大規模な同時音声認識をDSMS上で行うことも重要な課題となっている。
netstat -l してもポートが表示されない
(追記 : 20100723 Fri)
なんかよくわからないけど直ってた。
start_streams を実行するノードの問題だろうか?
とりあえず se00 から実行すれば問題なさそう
(思想)
低負荷時(要求入力速度<認識限界スループット)であれば
レイテンシは認識速度のみに依存
低認識精度でも高認識精度でも、認識処理以外にレイテンシが引っ張られることはない
高負荷時(要求入力速度>認識限界スループット)であれば
高認識精度だとバッファリングが生じるため
低認識精度時に比べレイテンシが激しく増大する
なので高負荷時には認識精度を低く、低負荷時には認識精度を高くしたい
負荷を測る指標として、認識器のアイドル時間も含めた瞬間平均流速を用いる。
この値が指定した範囲に含まれるとき、その範囲に該当するビーム幅を設定する、という実装
(問題)
この「負荷の指標」は正しく負荷を表しているか?
また、「負荷の指標」の値は現在のビーム幅にも依存してしまうという問題もある
(以下、要言語化)
やればわかる。学習機構自体は再考の必要あり?
あるいはごく簡単な学習機構のみを作り、手動で学習済みパラメータの入力も可能にする
学習機構のより適切な実装については論文中で「今後の課題」として書く。
論文の背景:オフライン音声認識、オンライン音声認識などの研究は今までなされてきたが、今日ではデータストリーム処理の重要性なども関連してきて、大規模な同時音声認識をDSMS上で行うことも重要な課題となっている。
2010年7月21日水曜日
StreamSR : スケールアウト性
 JNASモデルを用いてJNASテストセット(約20分音声)を評価
JNASモデルを用いてJNASテストセット(約20分音声)を評価ビーム幅は500,4000,8000の三通り
ビーム幅以外の設定値については割愛
ソースノード数1、認識ノード数4
赤線が認識時間(RTF)である。ビーム幅に応じて増加している。
緑線が誤認識率(WER)である。ビーム幅を落とすと誤認識率は増えるが、逆にビーム幅を一定程度以上高くしても誤認識率はあまり下がらなくなる。
StreamSR : 論文構成メモ
タイトル : データストリーム処理系を用いたスケーラブルな音声認識
・ Abstract
1. 導入
- DSMS
- 非構造化データ (音声)
- 背景 : コールセンターの顧客満足度向上など
- VoIP (インターネットコンファレンスなので)
- Streams + Julius を用いて実装した
- スケーラビリティ
- 認識ノードをスケールアウトすることによりスループットが向上
- 負荷向上時にビーム幅を落として認識精度を犠牲にレイテンシ、スループットが向上
2. 前提知識
- Streams
- Julius
- 主にビームサーチについて
3. システムの実装
4. 実験
- 実験条件
- 認識ノードのマシン構成
- 認識器、音響モデル、言語モデル、テストセット
- スケールアウトの実験
- 認識精度
- スループットの変化
- 負荷増大時ビーム幅変動機構の実験
- ビーム幅可変時、固定時(いくつかのビーム幅)で比較
- 認識精度、レイテンシ
- 考察
5. 結論
・ 参考文献
・ Abstract
1. 導入
- DSMS
- 非構造化データ (音声)
- 背景 : コールセンターの顧客満足度向上など
- VoIP (インターネットコンファレンスなので)
- Streams + Julius を用いて実装した
- スケーラビリティ
- 認識ノードをスケールアウトすることによりスループットが向上
- 負荷向上時にビーム幅を落として認識精度を犠牲にレイテンシ、スループットが向上
2. 前提知識
- Streams
- Julius
- 主にビームサーチについて
3. システムの実装
4. 実験
- 実験条件
- 認識ノードのマシン構成
- 認識器、音響モデル、言語モデル、テストセット
- スケールアウトの実験
- 認識精度
- スループットの変化
- 負荷増大時ビーム幅変動機構の実験
- ビーム幅可変時、固定時(いくつかのビーム幅)で比較
- 認識精度、レイテンシ
- 考察
5. 結論
・ 参考文献
2010年7月20日火曜日
StreamSR : ビーム幅学習(案)
--- 学習 ---
いくつかのビーム幅の値について、そのビーム幅でのスループットの最大値を計測する。
ビーム幅 : {b[0], b[1], ..., b[n-1]} , 最大スループット : {mth[0], mth[1], ..., mth[n-1]}
--- ビーム幅設定 ---
b[0] < b[1] < ... < b[n-1]
mth[0] > mth[1] > ... > mth[n-1]
n >= 3
を仮定する。
現在のスループットを th として、以下のようにビーム幅を設定
上記のアルゴリズムからは、ビーム幅の値が b[n - 1] に設定されることはない。
いくつかのビーム幅の値について、そのビーム幅でのスループットの最大値を計測する。
ビーム幅 : {b[0], b[1], ..., b[n-1]} , 最大スループット : {mth[0], mth[1], ..., mth[n-1]}
--- ビーム幅設定 ---
b[0] < b[1] < ... < b[n-1]
mth[0] > mth[1] > ... > mth[n-1]
n >= 3
を仮定する。
現在のスループットを th として、以下のようにビーム幅を設定
for ( i = n - 1; i >= 2; --i ) {
if ( mth[i] >= th ) {
setBeam(b[i - 1]);
return;
}
}
setBeam(b[0]);上記のアルゴリズムからは、ビーム幅の値が b[n - 1] に設定されることはない。

StreamSR : 評価の基準(応答時間)
1. 話者が発話を開始する
2. 話者が発話を終了し、クライアントプログラムが発話データをまとめる
3. クライアントプログラムがTCP経由でサーバにクエリを送る
↓
4. サーバがTCP経由でクエリを受け取る
5. クエリを処理する(音声認識処理)
6. サーバからTCP経由でクライアントに認識結果を送る
↓
7. クライアントが認識結果を受け取る
2.の終了から7.の終了までの応答時間を小さくすることを目標とする
---
模擬実験では、実際には発話はすでに完了しているため、
スケジュール表を元に、一定のタイミングで発話が完了したものとして
その時刻から応答時間を計測する。
「実際にTCP送信を始めた時刻」ではなく「スケジュール表に基づく発話終了時刻」
からの計測であるという点がポイントとなる。
2. 話者が発話を終了し、クライアントプログラムが発話データをまとめる
3. クライアントプログラムがTCP経由でサーバにクエリを送る
↓
4. サーバがTCP経由でクエリを受け取る
5. クエリを処理する(音声認識処理)
6. サーバからTCP経由でクライアントに認識結果を送る
↓
7. クライアントが認識結果を受け取る
2.の終了から7.の終了までの応答時間を小さくすることを目標とする
---
模擬実験では、実際には発話はすでに完了しているため、
スケジュール表を元に、一定のタイミングで発話が完了したものとして
その時刻から応答時間を計測する。
「実際にTCP送信を始めた時刻」ではなく「スケジュール表に基づく発話終了時刻」
からの計測であるという点がポイントとなる。
2010年7月14日水曜日
StreamSR : 入力データレートとスループット
「CPUインテンシブならば入力データレート ∝ スループットになる」というのは思い込みだった。
同じ実験で測定した入力データレートとスループットを図示する。
下図を見る限り、入力データレートではなくスループットで学習すればうまくいくかも?
学習の方法、ビーム幅の決定方法は未定
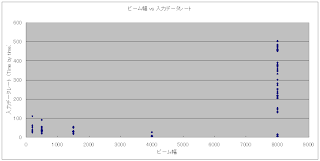

同じ実験で測定した入力データレートとスループットを図示する。
下図を見る限り、入力データレートではなくスループットで学習すればうまくいくかも?
学習の方法、ビーム幅の決定方法は未定


2010年7月13日火曜日
StreamSR : ビーム幅と入力データレート
トリビアルなテストデータを用いて、ビーム幅に対する入力データレートを測定した。
ソースノード数 : 4、認識ノード数 : 16
一回目(認識ノードのCPU使用率は100%)

二回目(CPU使用率不明)

---
補足
ビーム幅を x と置くと、音声処理時間(実時間係数 : RTF)は Ax+B で定式化される(はず)
データ入力でバッファリングが起こる、などの関係上、入力データレート ≒ スループット となる。
なので、入力データレート ∝ 1/(Ax+B) になる(はず)
---
確認事項
/tmp/ /dev/shm/ などにファイルを置いて試してみる。
今回のテストでは低いビーム幅から高いビーム幅の順にスクリプトを回したが、
逆に高いのから順にすると結果が変わるか確認。
ソースノード数 : 4、認識ノード数 : 16
一回目(認識ノードのCPU使用率は100%)

二回目(CPU使用率不明)

---
補足
ビーム幅を x と置くと、音声処理時間(実時間係数 : RTF)は Ax+B で定式化される(はず)
データ入力でバッファリングが起こる、などの関係上、入力データレート ≒ スループット となる。
なので、入力データレート ∝ 1/(Ax+B) になる(はず)
---
確認事項
/tmp/ /dev/shm/ などにファイルを置いて試してみる。
今回のテストでは低いビーム幅から高いビーム幅の順にスクリプトを回したが、
逆に高いのから順にすると結果が変わるか確認。
2010年7月9日金曜日
StreamSR : 入力ボトルネック
以前からの変更点
・システムの入力を file: から stcp: に変更
・学習ユニットと認識ユニットを統合
問題点
・stcp: に変更したからなのか、入力データレートが非常に低い
・認識ノードのCPU使用率が100%までいかない
解決案
・無理矢理すべての入力をひとつの file: からの入力にまとめる
・stcp: を使う場合、TCP入力スクリプトを改良、音声形式をMFCCに変更、など
・システムの入力を file: から stcp: に変更
・学習ユニットと認識ユニットを統合
問題点
・stcp: に変更したからなのか、入力データレートが非常に低い
・認識ノードのCPU使用率が100%までいかない
解決案
・無理矢理すべての入力をひとつの file: からの入力にまとめる
・stcp: を使う場合、TCP入力スクリプトを改良、音声形式をMFCCに変更、など
2010年7月6日火曜日
StreamSR : 現状メモ(2)
(言語化されていない記事)
学習ユニット
Decoderでスループットが低い場合、当然それに従って、バッファリングが生じて入力データレートも低くなってしまう。(ボトルネック)
それでも、学習ユニット内のデコーダの数を一つに限定してしまえば、ビーム幅vsスループットの学習はできる。
問題は、「認識ユニットの入力データレート増大時にビーム幅を下げる」機能の実装である。
当然だが、認識器のスループット≦入力データレートにしかならない上に、
ボトルネックの影響があるので「ボトルネックがなかった場合の」入力データレートを知ることはできない。
(この値がわかるのであれば、それに応じてビーム幅の変更が可能である。)
---
ビーム幅vsスループット、あるいはビーム幅vs(ボトルネック付き)入力データレートの学習はできるので、現在の観測された入力データレートが学習値に近づいた場合にビーム幅を下げる、というような実装ならば可能。
学習ユニット
Decoderでスループットが低い場合、当然それに従って、バッファリングが生じて入力データレートも低くなってしまう。(ボトルネック)
それでも、学習ユニット内のデコーダの数を一つに限定してしまえば、ビーム幅vsスループットの学習はできる。
問題は、「認識ユニットの入力データレート増大時にビーム幅を下げる」機能の実装である。
当然だが、認識器のスループット≦入力データレートにしかならない上に、
ボトルネックの影響があるので「ボトルネックがなかった場合の」入力データレートを知ることはできない。
(この値がわかるのであれば、それに応じてビーム幅の変更が可能である。)
---
ビーム幅vsスループット、あるいはビーム幅vs(ボトルネック付き)入力データレートの学習はできるので、現在の観測された入力データレートが学習値に近づいた場合にビーム幅を下げる、というような実装ならば可能。
2010年7月2日金曜日
User-defined sources are able to produce multiple streams.
IBMInfoSphereStreams-LangRef.pdf の28ページ (35/100) より
2010年7月1日木曜日
StreamSR : 現状の問題
ユーザ定義ソースからpunctuation0()が送られていない?
(追記 : 20100702)
先生に教えてもらった -o オプションが spadec --help から見つからなかった。
-U オプションかな?と思って試してみたけど、うまくいかなかった。
(追記2 : 20100707)
うまくいった。単純に punctuation を送るところまで処理がいっていなかっただけらしい
修正
(追記 : 20100702)
-U オプションかな?と思って試してみたけど、うまくいかなかった。
(追記2 : 20100707)
うまくいった。単純に punctuation を送るところまで処理がいっていなかっただけらしい
修正
登録:
投稿 (Atom)